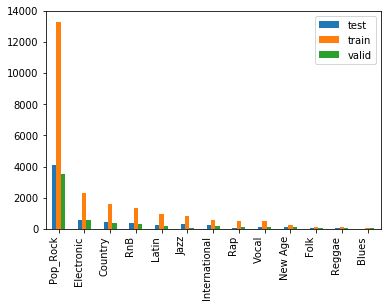
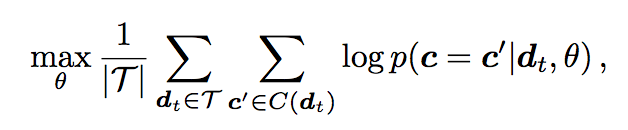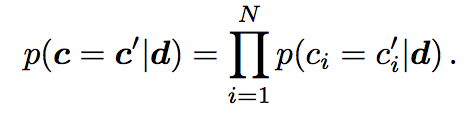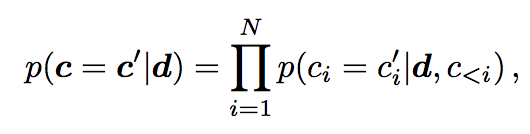Figure 3.1: The distribution of each class within our dataset
MUSIC STYLES
Richard Godden
github.com/goddenrich/
Yogesh Garg
github.com/yogeshg/
Abstract
Recent analysis of state of the art neural networks trained to transcribe music from audio[1] show that they do little better than learning the exact combinations of notes in a chord. Chords constructed of even two notes that the network hasn’t seen together are almost always misclassified. We theorise that this is because the representations of notes and chords hold no semantic meaning. Inspired by models used widely in natural language processing we experiment whether embeddings of chords using skip-gram models hold semantic meaning for songs.
1. Introduction
Inspired by the good results skip-gram embeddings for words have obtained in a variety of natural language processing tasks we decided to explore whether similar methods to obtain chord embeddings would improve a variety of tasks within the music space. Theoretically these embeddings provide semantic meaning to the representations of chords and could be useful to do a wide variety of tasks including genre classification and transcription. We collected a large dataset of midi files and extracted the chord sequence from them. We implemented a model proposed in the paper chord2vec[2] to learn embeddings. We then experimented to see if those embeddings were useful to train a classifier to predict the genre of a piece of music. We conclude that the embeddings were not useful for the task. We suggest possible reasons for this and what the next steps could be to investigate further.
2. Related work
The word2vec[3] model has been used extensively and very successfully for a wide variety of tasks within natural language processing. The model learns embeddings for words by training to predict the current word vector embedding in a sequence of words from the embeddings of the words that surround that word. This encourages the structure of the sequence of words to be reflected in the space of embeddings. A result is that words with similar meaning are close to each other in the embedding space and certain vector arithmetic can be performed on word representations that display semantic meaning.
Madjiheurem[2] proposes and tests three method inspired by the methods in word2vec[3] which learns embeddings for chords in a similar manner to words. The methods they propose represent chords as a multi-hot vectors indicating the notes present in the chord. The methods they use successfully learn embeddings for the the datasets limited to classical music. we used the autoregressive model to train embeddings on the JSChorals dataset to embed our chords.
3. Data set
We constructed our dataset by combining multiple information sources. The million song database[4] is a database of metadata and audio features for 1,000,000 pieces of popular music. It does not include any audio or midi files but was used to identify links between labels and midi files. This dataset became the core Identifier for building our dataset of chord in a song. The Lakh dataset[5] is a collection of over 46,000 midi files which have been matched to the million song dataset. Each midi file contains a snippet of a transcription of the song in midi format. The allmusic genre labels[6] is a dataset of genre labels for 400,000 of the million song database and includes 13 classes.
Midi files are a stream of signals to a synthesizer. The signals tell the synthesizer among other things to turn on or off a specific note on a particular channel. We chose to represent a song as the progression of chords within that song. This representation removed the information about the duration of chords and the instrumentation. Each chord was represented as the list of notes present in that chord. each time a signal is received to to turn a note on or off a new chord is created reflecting that change. We limited the possible notes to the range of a concert piano giving us a maximum range of 88 notes. To do this we used midi2csv[7] to convert the midi signals into a format that could be interpreted by our custom python script. The final output is a dataset of a collection of songs represented by their chord sequence and their genre labels for over 35,000 songs.
The resulting labeled dataset presented two challenges. Firstly it was heavily skewed with the majority class dominating the data. We implemented various techniques to deal with this during learning including a weighted loss function and balancing the dataset. Secondly it took up over 5GB of memory before converting to multi hot vectors or embeddings. This meant the full dataset could not be easily processed at runtime. We used generators and multi-threading to speed up the computations during training and testing.
Figure 3.1: The distribution of each class within our dataset
4. Methods
4.1 Embeddings
This sequence of chords is used by the embeddings model to convert into chord vectors, which are then applied to the multi-hot vectors in the classifier model. Because ours is a much bigger dataset than the ones used to train chord2vec, we chose a subset of 100 songs to train the embeddings. The chord2vec paper discusses three ways to create the embeddings -- Linear, Autoregressive, and sequence to sequence. All the three are forms of skip-gram model and the difference is in the assumptions of probabilities of notes within a chord. Linear model assumes that all the notes in a chord are independent and tries to model the probabilities from the context (chords before and after). Autoregressive model assumes that the probability of a note in a chord is conditional on the lower notes already being played in the chord. Suppose d is our current chord and T is the set of chords in the song and C(di) is the set of context chords of chord di the objective of these models is to maximize:
4.1.1 Bilinear
The Bilinear model is the simplest adaptation of the skip-gram model where instead of a one hot encoding a chord has a multi-hot encoding. As a simplifying assumption in this model the notes in a chord are assumed to be independent of each other ie:
where ci  {1,0} where 1 denotes note i is present in the chord.
{1,0} where 1 denotes note i is present in the chord.
4.1.2 Autoregressive
In this model the notes in a chord are not assumed to be independent but instead calculated according to the following formula:
the probabilities of note i in a chord depends on the notes lower than it.
4.1.3 sequence-to-sequence
In this model instead of a vector of one hot encodings the music is represented by a sequence of tokens representing the constituent notes of each chord and each chord separated with a special symbol. We have left implementing this model for future works.
We trained on the JSB chorales dataset to confirm the results and then on the chords from 100 midi files from the Lakh Song Database(LSD)
Table 1: Average negative log likelihood per chord for the test set
(Adapted from Chord2Vec / *our contribution)
Model | JSB Chorales | Nottingham | MuseData | Piano-midi.de | Mix | 100 songs from LSD |
Random | 61.00 | 60.99 | 60.99 | 60.99 | 60.99 | |
Marginal | 12.23 | 10.44 | 23.75 | 17.36 | 15.26 | |
Linear c2v | 9.77 | 5.76 | 15.41 | 12.68 | 12.17 | |
Autoreg. c2v | 6.18* | 3.98 | 14.49 | 10.18 | 7.42 | 7.89* |
Seq2Seq c2v | 1.11 | 0.50 | 1.52 | 1.78 | 1.22 |
4.2 Neural Network
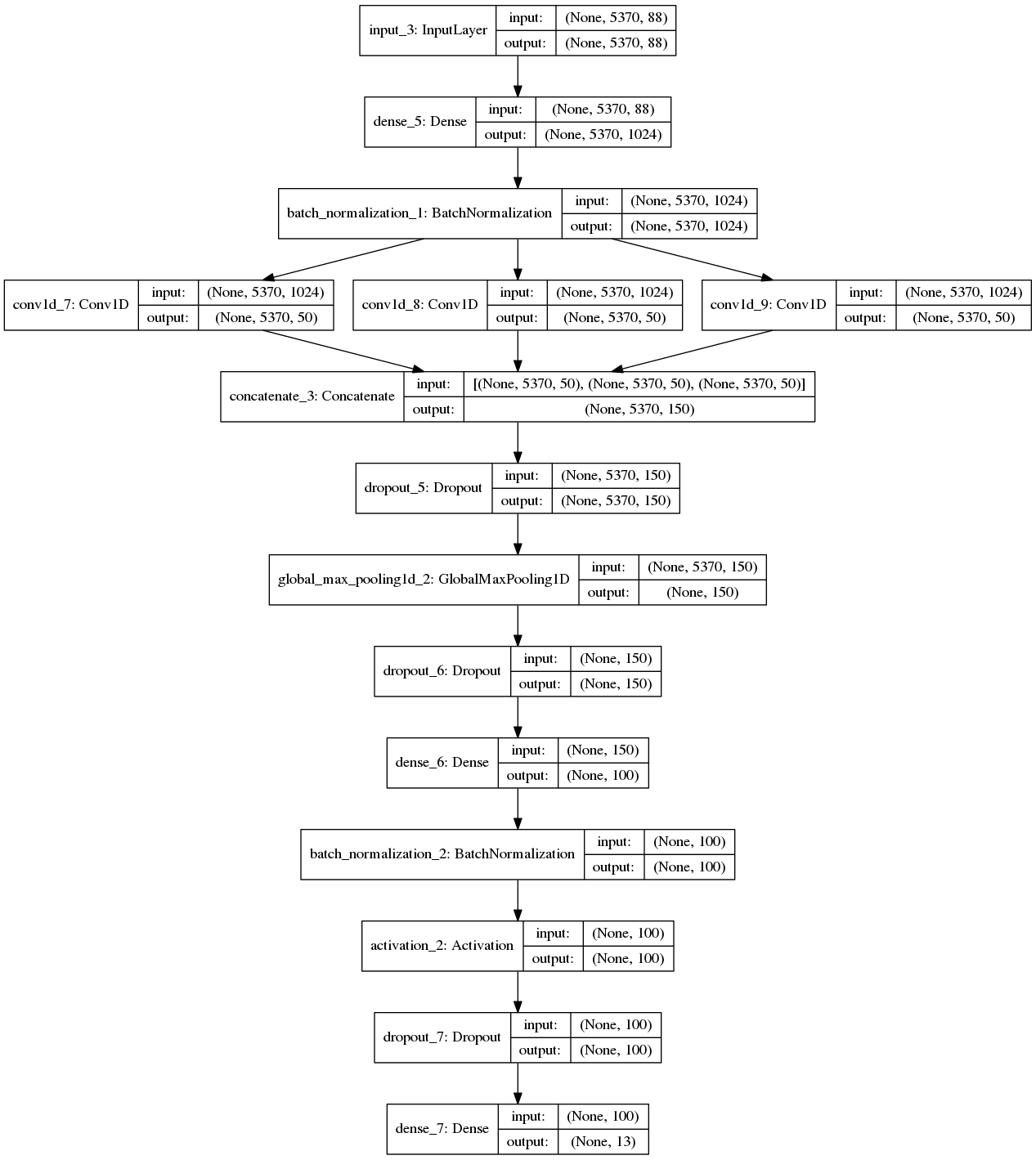
We use an architecture as displayed below. We take in an input, apply the embeddings trained by chord2vec model using a non-trainable dense layer. We do batch normalization, and take convolutions of different sizes. We experiment with convolutions of sizes 1 to 3 and 1 to 10. A maximum pooling layers is applied to the concatenation of these layers. We pass this through a dense layer before a final categorization layer.
Figure 4.2: Neural Network with 1 to 3 Convolutions
4.2.1 Training
We convert the list of chords and list of labels that we generate as our dataset into multi-hot and one-hot vectors respectively. This was a time consuming step, thus we had to use multi threading to speed up the process. A single thread took up to 30 minutes on a modern 24-core, 128GB machine. Using a pool of 20 threads to process the data, we could process it in under 5 minutes. We also had to pad the sequence of chords with zeros to match the size of each song. This would require a lot of memory, so we did this only in batches, using a custom batch generator, based on Keras API. With these optimisations, each epoch took about 15 minutes on a machine with the given specifications. To train our model, we use an early stopping criteria with a patience of 10 epochs.
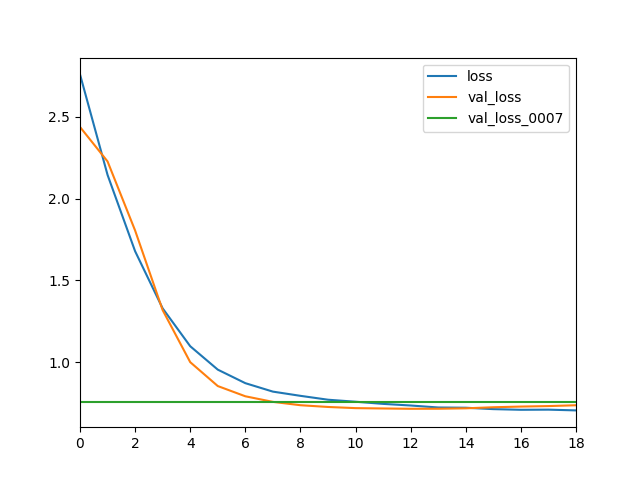
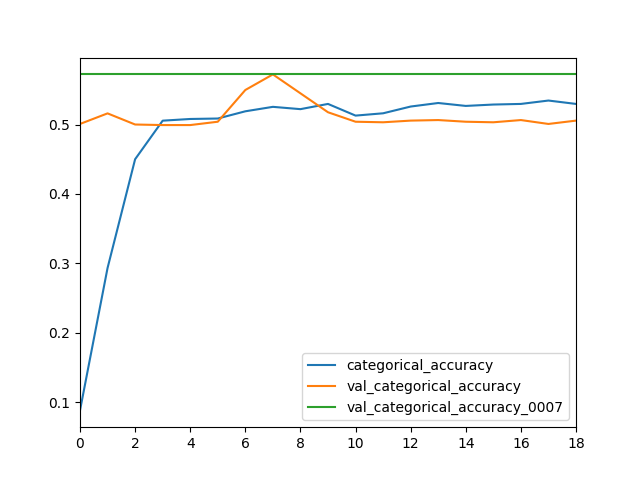
Figure 4.2.1.1: Loss and Accuracy during training
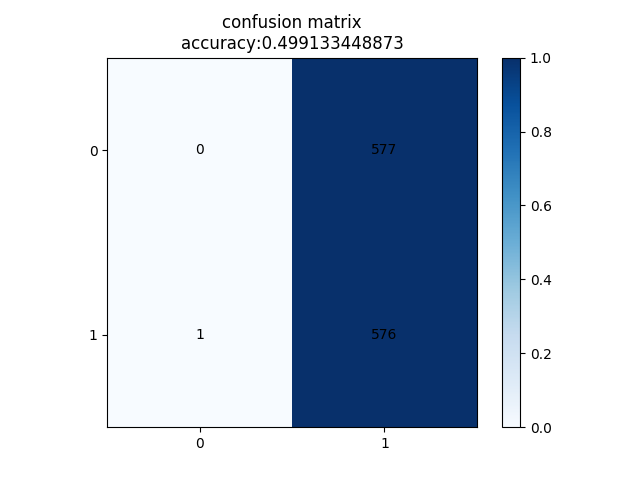
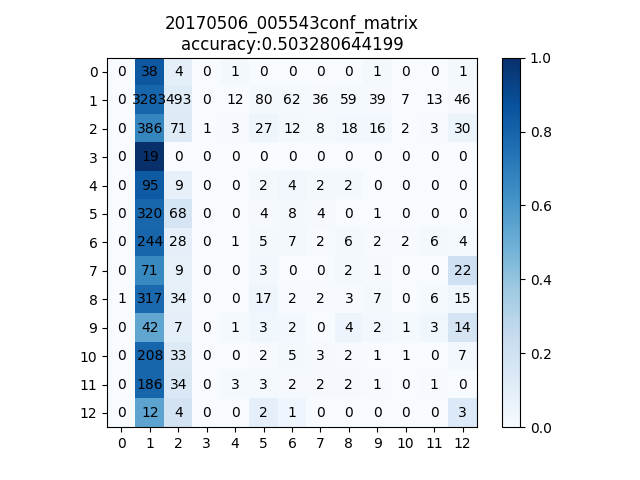
Figure 4.2.1.2: Confusion Matrix for the last classifier
5. Results
We ran a number of experiments with different architectures, but they all performed pretty similarly. We discuss a few representative experiments below:
5.1 No-Embeddings vs. with embeddings
We observe that the model with embeddings performs worse than the model without embeddings. But it is important to notice that the number of parameters are much less in the model with embeddings. Using a max pooling layer in no-embeddings model does not make sense as that simply adds up all the notes ever played in the song. That’s why we simply flatten the no-embeddings model. This causes the model to lose its time-invariance, which is why this model is not scalable to potentially new music or pieces that are much longer or shorter than those seen while training.
Table 5.1: Accuracies for No-Embeddings vs. Embeddings Model
Model (Num. Params) | Best Epoch | Training Accuracy | Validation Accuracy |
No-Embeddings (80,578,339) | 16 | 65.06% | 60.59% |
Embeddings | 8 | 52.21% | 57.22% |
5.2 Kernel sizes vs. number of filters
We did another experiment by increasing the size of convolutional kernel and decreasing the number of kernels. Doing so does not improve the accuracy. Number of filters is therefore, much more important than the size of convolutional filter.
Table 5.2: Accuracies for Models with different number of Kernel Sizes or Number of Filters
Kernel Sizes, Num. Filters | Best Epoch | Training Accuracy | Validation Accuracy |
(1 to 3, 50) | 8 | 52.21% | 57.22% |
(1 to 9, 5) | 4 | 51.84% | 51.90% |
5.3 Multi-class classifier
We train our classifier to do a multi class classification on the entire dataset with a loss function accounting for class weight equal to the inverse of the frequency of that label. This also results in the majority class chosen for the task.
Figure 5.2: Confusion Matrix for multi-class classifier
6. Conclusions and next steps
Our classifier fails to learn anything reasonable. It simply classifies everything as the majority class. (We got similar behavior when we tried on a multi-class classifier with a clear majority class). We conclude that the current embeddings do not have semantic meaning for the genre classification problem. This is counter to our intuition and we believe that perhaps learning embeddings from a larger dataset might be required. Another way would be to unfreeze the embeddings layer while training for multiple independent tasks that share semantics in the song. We provide the source code of our project on Github [8] for further exploration of this task.
7. References
[1] Kelz, Rainer, and Gerhard Widmer. "An Experimental Analysis of the Entanglement Problem in Neural-Network-based Music Transcription Systems." arXiv preprint arXiv:1702.00025 (2017).
[2] Madjiheurem, Sephora, Lizhen Qu, and Christian Walder. "Chord2Vec: Learning Musical Chord Embeddings."
[3] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
[4] Bertin-Mahieux, Thierry, et al. "The Million Song Dataset." ISMIR. Vol. 2. No. 9. 2011.
[5] Raffel, Colin. Learning-Based Methods for Comparing Sequences, with Applications to Audio-to-MIDI Alignment and Matching. Diss. COLUMBIA UNIVERSITY, 2016. http://colinraffel.com/publications/thesis.pdf
[6] allmusic http://www.ifs.tuwien.ac.at/mir/msd/
[7] John Walker - http://www.fourmilab.ch/webtools/midicsv/
[8] Richard Godden, and Yogesh Garg - https://github.com/yogeshg/music-styles/